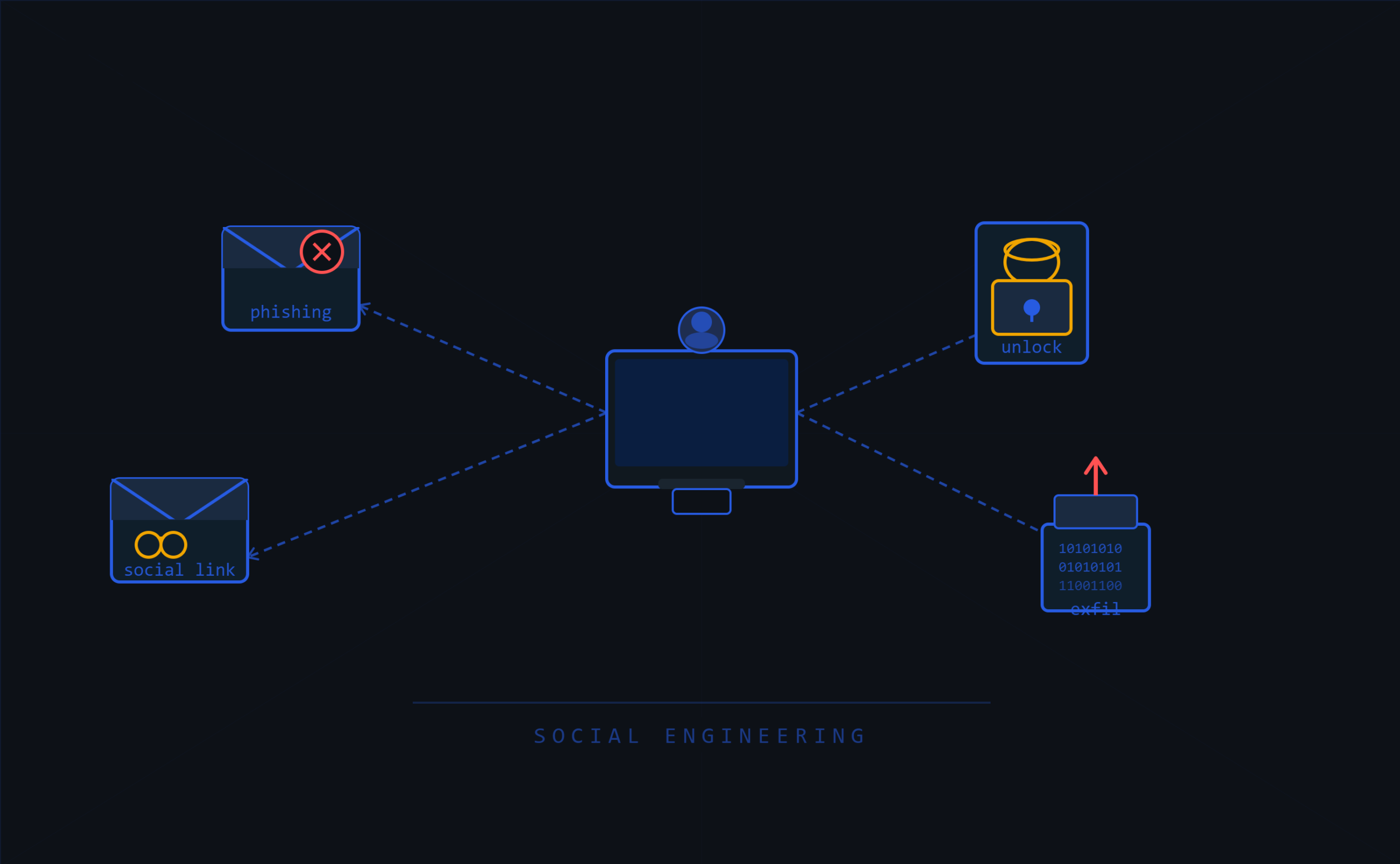
AI-beeldgeneratie maakt het steeds makkelijker om geloofwaardig visueel bewijs te maken. Dat verandert social engineering: een verhaal hoeft niet langer alleen verbaal overtuigend te zijn, maar kan worden ondersteund met foto’s, screenshots of aangepaste afbeeldingen.
Collin, stagiair Platform Engineering bij Warpnet kreeg de opdracht om een self-hosted tool te bouwen waarmee organisaties gecontroleerd kunnen worden getoetst op hun weerbaarheid tegen AI-ondersteunde social engineering. Deze blogpost beschrijft hoe die stageopdracht is aangepakt en wat hij daarvan heb geleerd. De belangrijkste les: het genereren van beelden is niet het moeilijkste deel. De waarde zit vooral in goede scope, realistische scenario’s, controle over data, consistente persona’s en een zorgvuldige vertaling naar verdedigbare maatregelen.
De persona-en-beeld-loop
Teams die social-engineeringtests uitvoeren, lopen telkens door ongeveer dezelfde cyclus. Voor AI-ondersteunde scenario’s heb ik die cyclus vertaald naar zes stappen:
- Scope: bepaal welk vertrouwen, proces of controlemoment je wilt testen.
- Pretext: bouw een verhaal dat past binnen de opdracht en de organisatie.
- Dossier: genereer een persona met biografie, werkgeschiedenis en basismateriaal.
- Beeldstrategie: kies of je snelle beelden, consistente personages of aanpassingen aan bestaande foto’s nodig hebt.
- Validatie: controleer of de beelden technisch en inhoudelijk geloofwaardig zijn.
- Terugkoppeling: vertaal de testresultaten naar concrete verbeteringen in processen en awareness.
De tool ondersteunt vooral stap 3 tot en met 5. De eerste en laatste stap blijven mensenwerk: daar worden de ethische grenzen, klantafspraken en leerdoelen bepaald.
1. Scope: test vertrouwen, niet alleen herkenning
Een veelgemaakte fout bij AI-awareness is dat de nadruk volledig komt te liggen op “AI herkennen”. Dat is nuttig, maar onvoldoende. De betere vraag is: welke processen gaan ervan uit dat beeldmateriaal automatisch betrouwbaar is?
Neem een volgende scenario als voorbeeld. In een algemene ruimte hangt een brandalarm. Een tester maakt daar een foto van en laat die later aanpassen, zodat het lijkt alsof een led brandt.


Daarmee kan een onderhoudsverhaal overtuigender lijken dan het eigenlijk is:
“Ik ben Jeroen van * Installatietechniek. Ik kreeg een melding dat er iets mis was met één van jullie brandalarmen.”
Het punt van zo’n test is niet dat medewerkers perfecte AI-detectie moeten uitvoeren. Het punt is dat een organisatie wil weten of medewerkers leveranciers, monteurs en spoedverzoeken via bekende kanalen controleren. Een foto kan een verhaal versterken, maar mag nooit de verificatie vervangen.
2. Stack: houd gevoelige testdata lokaal
Publieke beeldgeneratiemodellen kunnen uitstekende resultaten leveren, maar social-engineeringtests bevatten vaak gevoelige klantcontext: foto’s van locaties, interne scenario’s, persona’s en soms portretmateriaal van testers. Daarom is voor deze tool gekozen voor een self-hosted opzet.
De Docker-stack bestaat uit vier componenten:
- Flask: de webapp waarin dossiers, uploads en workflows worden aangestuurd.
- ComfyUI: de engine voor beeldgeneratie en inpainting-workflows.
- Ollama: de lokale LLM-container voor biografieën en werkervaring.
- Kohya-SS: de container voor het trainen van LoRA’s.
Deze opzet geeft meerdere voordelen: de data blijft lokaal, workflows zijn herhaalbaar en verschillende beeldtaken kunnen als losse modules worden opgebouwd.
3. Dossier: bouw de persona vanuit context
Een goede persona begint niet bij een gezicht, maar bij context. De tool vraagt daarom eerst basisgegevens uit, zoals naam, leeftijd, woonplaats, sector, functie, werkplek, hobby’s en opleidingsniveau. Die gegevens worden via SQLAlchemy opgeslagen in de database.
Daarna gebruikt de tool SerpAPI om relevante context op te halen. Voor een fictieve systeembeheerder uit Assen kunnen dat bijvoorbeeld deze zoekqueries zijn:
bekende bedrijven ICT / Software Assen Nederlandhogeschool ICT / Software Assen Nederland
Het resultaat is een JSON-bestand met zoekresultaten:
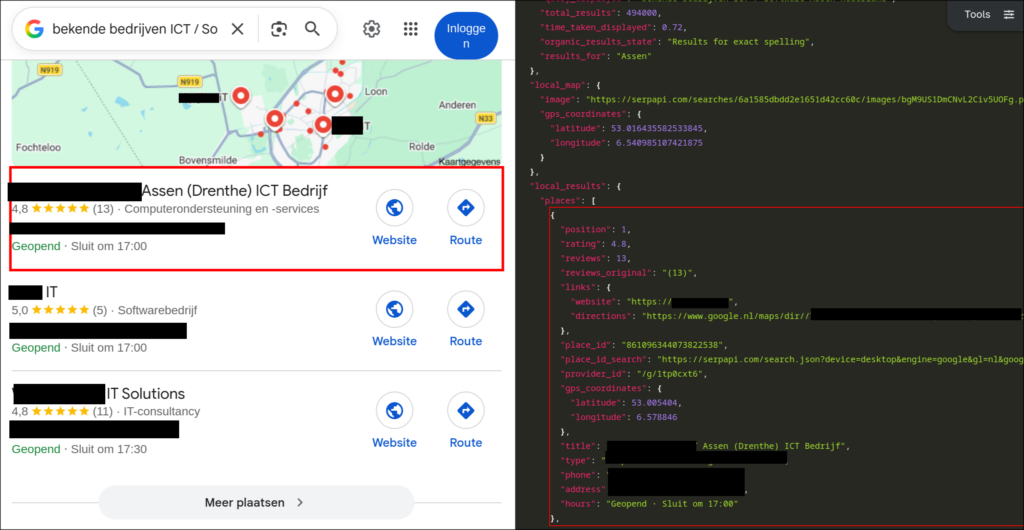
Die JSON gaat naar Ollama. Het LLM gebruikt de informatie om een realistische, maar fictieve, biografie en werkgeschiedenis op te bouwen.
BIOGRAFIE:
Henk de Vries is een ervaren systeembeheerder met meer dan 25 jaar ervaring
in de ICT-branche. Na zijn afstuderen aan de Saxion Hogeschool voor HBO-ICT
begon hij zijn loopbaan bij een middelgrote ICT-firma in Assen. Hij
specialiseerde zich in systeembeheer en netwerkbeheer en werkte zich op tot
senior-beheerder. In 2016 verliet Henk de firma om als zelfstandig
systeembeheerder te gaan werken. Sindsdien heeft hij een breed scala aan
klanten geholpen met hun ICT-problemen. In zijn vrije tijd houdt hij van
hardlopen en zwemmen.
WERKERVARING:
2020-heden: Zelfstandig systeembeheerder
2016-2020: Senior System Administrator bij ********* IT Services Assen
2012-2016: System Administrator bij ********* Hogeschool
2007-2012: Netwerkbeheerder bij ********* ICT
1999-2007: Systeembeheerder bij ********* ICTDe output is geen eindpunt, maar startmateriaal. Een pentester kan de persona aanpassen aan de opdracht, inconsistenties verwijderen en details toevoegen die relevant zijn voor het scenario.
Vanuit hetzelfde dossier kan ook een basisportret worden gegenereerd. Dat geeft de persona een visuele identiteit voordat er eventueel een LoRA wordt getraind.

4. Beeldstrategie: kies de lichtste workflow die past
Niet elk scenario vraagt om dezelfde technische aanpak. De tool ondersteunt daarom drie soorten beeldwerk:
- Out-of-the-box generatie: snel realistische afbeeldingen maken wanneer gezichtsconsistentie niet belangrijk is.
- Consistente persona’s: een LoRA trainen zodat dezelfde persoon in meerdere beelden herkenbaar blijft.
- Inpainting: bestaande beelden aanpassen of een persoon in een bestaande foto plaatsen.
De keuze hangt af van het testdoel. Als een afbeelding maar één keer wordt gebruikt, is out-of-the-box generatie vaak genoeg. Als een persona op LinkedIn, in e-mail en in meerdere scenariofoto’s terugkomt, wordt gezichtsconsistentie belangrijker. Als de test draait om visueel bewijs uit een bestaande omgeving, is inpainting meestal de betere route.
Out-of-the-box generatie
Voor snelle beelden gebruikt de tool een ComfyUI-workflow met het checkpoint UltraReal Fine-Tune van Danrisi, beschikbaar via Civitai. Een checkpoint functioneert als basismodel. Een LoRA kan daar bovenop worden geladen om het model te specialiseren in een persoon, object of stijl.

prompt: d1g1cam, Cooling tower, nighttime, industrial setting, large cylindrical structure illuminated by orange lights, red warning lights at the top, steam billowing upwards, dark blue sky with lots of stars and aurora, reflection in still water below, surrounding industrial landscape, power lines and pylons to the right, scattered faintly lit buildings in the distance, clear and sharp image quality, long exposure, tranquility, calm atmosphere

prompt: 40 year-old CEO having a presentation at defcon, formal clothing, slightly overweight
De checkpoint is gebaseerd op FLUX.1-dev en is gericht op beelden die minder studio-perfect ogen. Dat is belangrijk: te schone afbeeldingen vallen vaak juist sneller op.
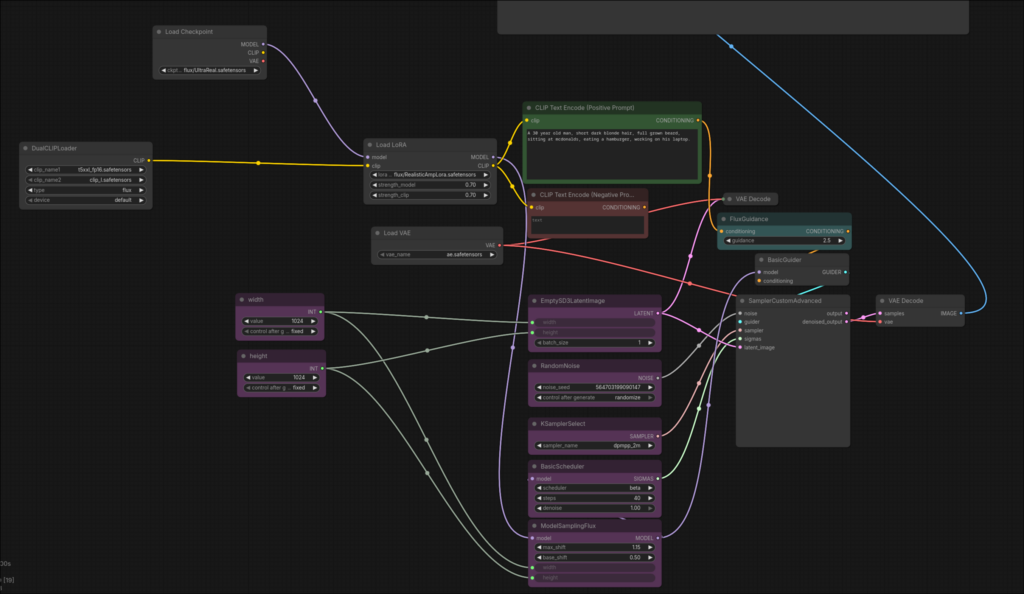
In deze workflow wordt ook de Realistic Amplifier for UltraReal Fine-Tune-LoRA van dezelfde maker geladen om het realisme verder te verhogen
Smart Fill
Smart Fill past een geselecteerd deel van een bestaande afbeelding aan. De tester tekent een masker over het gebied dat moet veranderen en geeft een prompt mee. FLUX vult dat gebied vervolgens opnieuw in.
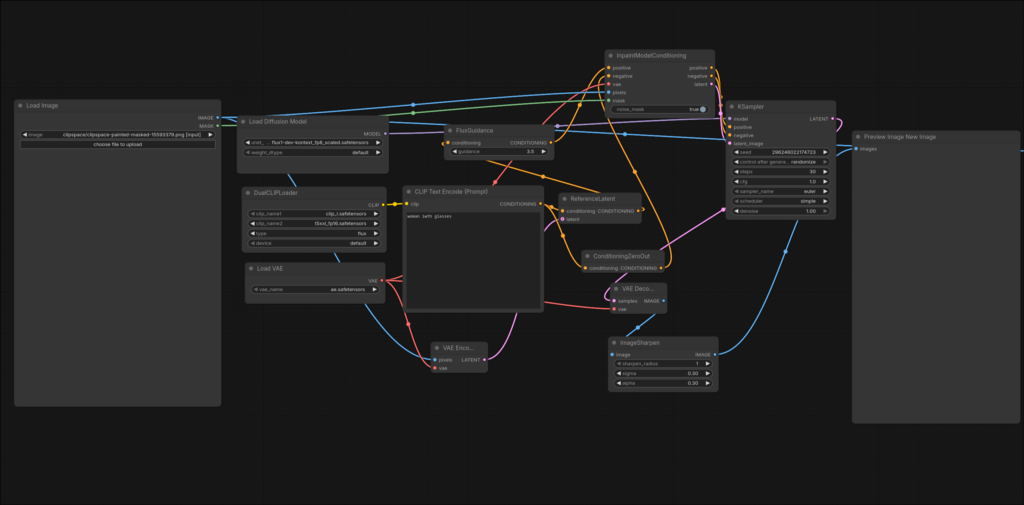
Dit is de workflow die ook in het brandalarmvoorbeeld wordt gebruikt. In een geautoriseerde opdracht kan dit helpen om te testen of medewerkers visueel bewijs te snel vertrouwen, bijvoorbeeld wanneer een afbeelding zogenaamd een storing, badge, sticker of interne situatie toont.
Insert Character
Insert Character gebruikt de Flux-Insert-Character-workflow van Kinelite. De workflow plaatst een persoon in een bestaande afbeelding op basis van vier inputs:
- Source Image: de achtergrond of locatie.
- Masker: de plek waar de persoon moet komen.
- Reference Image: het gezicht of lichaam van de persoon die moet worden geplaatst.
- Prompt: de beschrijving van houding, kleding en context.
Source:

Mask:

Reference:

Resultaat:

Dit voorbeeld is bewust overdreven. Het laat vooral zien dat de workflow belichting, positie en compositie kan combineren. Voor echte opdrachten gebruik je uiteraard realistische scenario’s binnen de afgesproken scope.
5. Consistentie: train een LoRA wanneer een persona terugkomt
Het grootste probleem bij meerdere gegenereerde beelden is consistentie. Je kunt dezelfde prompt opnieuw gebruiken, maar het gezicht, de lichaamsbouw en kleine herkenbare kenmerken veranderen vaak alsnog. Voor een persona die vaker terugkomt, is dat niet goed genoeg.
Daarvoor gebruikt de tool een Low-Rank Adaptation, meestal LoRA genoemd. Een LoRA is een kleine toevoeging aan een bestaand diffusion-model. Door het model op een dataset met afbeeldingen van één persoon te trainen, leert de LoRA welke kenmerken bij die persoon horen.
De tool ondersteunt twee datasetroutes:
- Fictieve persoon: start vanuit één gegenereerde afbeelding en maak daar meerdere variaties van.
- Echte persoon: upload foto’s van een tester.
Fictieve persona’s
Voor fictieve persona’s gebruikt de tool een workflow van Mickmumpitz, een AI-YouTuber die veel met diffusion-modellen werkt. De workflow kan vanuit één referentieafbeelding meerdere variaties maken waarbij de gezichtskenmerken redelijk consistent blijven.

De workflow gebruikt Qwen 2.5. Die neemt een referentieafbeelding en genereert op basis van een prompt nieuwe beelden.
A hyper-realistic, low-angle cinematic shot of the exact person from the reference image, sitting on a natural surface in a sun-drenched park. The camera is positioned low, looking up towards the subject.
Subject & Pose: The person is captured with their head tilted back, eyes gazing upward into the sky with a serene, neutral expression. Every facial feature—the eye shape, jawline, and nose bridge—must be an exact 1:1 match to the reference person. The hair texture and body proportions remain identical.
Atmosphere & Lighting: Bright, direct afternoon sunlight creating natural, high-contrast highlights on the skin and hair. Soft environment bounce-light fills the shadows. The sky above is a clear, brilliant blue with subtle lens flare.
Environment: The background consists of out-of-focus green tree canopies and a vast open sky, rendered with a creamy, professional bokeh. The person is wearing the identical white t-shirt and shorts from the reference image, with realistic fabric textures and sun-lit fibers.
Technical Quality: Shot on a Sony A7R IV, 35mm wide-angle lens, f/8 for deep clarity on the subject. High-resolution 8k photography, RAW format. Meticulous detail on skin pores, natural skin oils, and individual hair strands. Strictly no digital smoothing, no cartoon shading, and no 3D-render aesthetic. High-fidelity photographic realism.In ComfyUI kun je zelf bepalen hoeveel afbeeldingen worden gegenereerd:
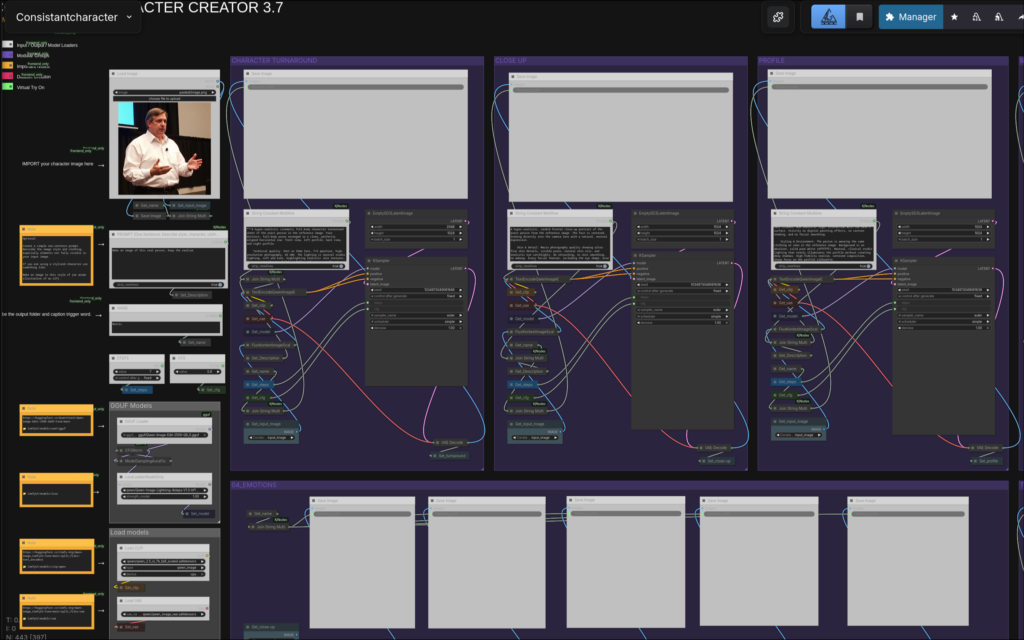
Voor deze tool is de oorspronkelijke hoeveelheid van 22 afbeeldingen aangehouden als dataset voor LoRA-training.
Echte personen
Voor echte personen is de dataset minder technisch, maar kwaliteitscontrole blijft belangrijk. De webapp bevat daarom een uploadscherm waarmee foto’s in bulk kunnen worden toegevoegd en bijgesneden naar 1024×1024 pixels.
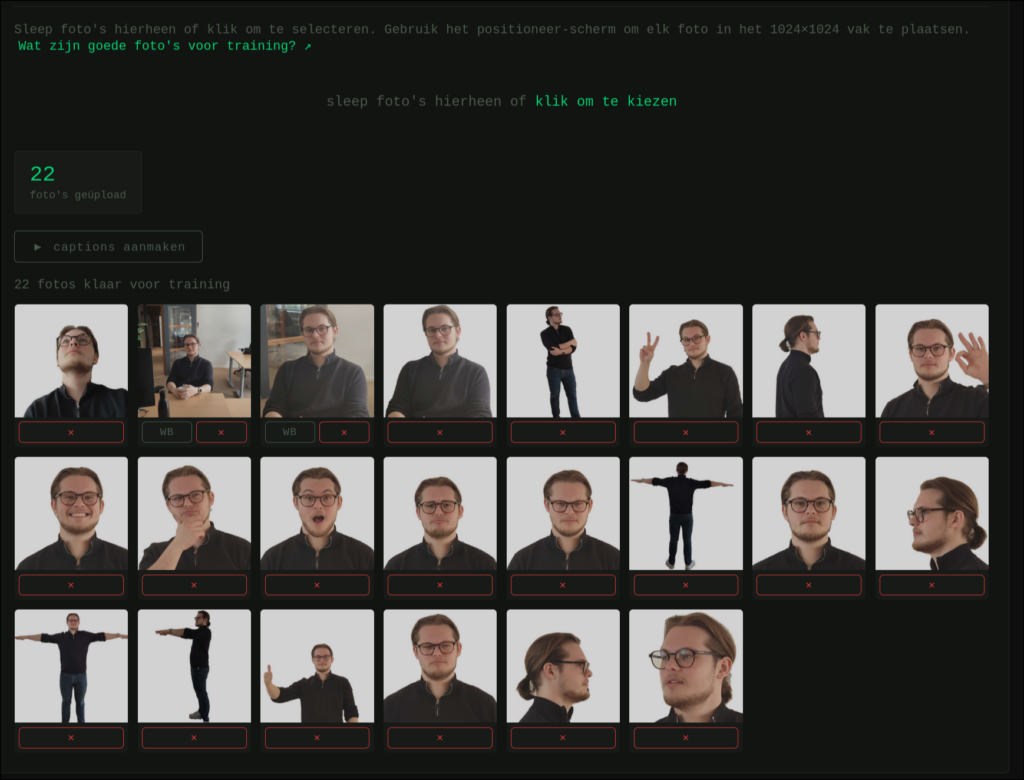
Daarna maakt een workflow de achtergrond wit. Daarmee verklein je de kans dat de LoRA achtergrondpatronen leert in plaats van alleen persoonskenmerken. Een paar foto’s met achtergrond zijn geen probleem, maar de achtergrond mag de dataset niet domineren.
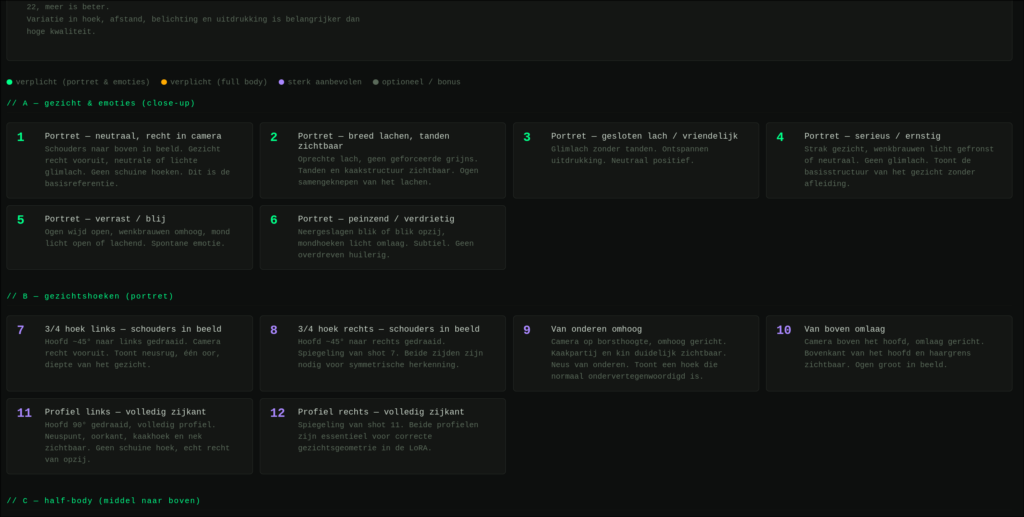
De tool bevat ook een gids die uitlegt welke foto’s samen een bruikbare dataset vormen.
6. Training: gebruik loss als signaal, niet als oordeel
Voor training heeft elke afbeelding een caption nodig: een tekstbestand dat beschrijft wat er op de afbeelding staat. De Mickmumpitz-workflow gebruikt Florence-2 om captions automatisch te genereren. Die captions worden samen met de afbeeldingen in de datasetmap geplaatst.
Daarna start de tool via de Kohya-SS API een LoRA-training. De meeste instellingen blijven gelijk, zoals resolutie, modelpad en trainingslocaties. Per persona veranderen vooral de naam, datasetmappen en trainingsstappen.
Een belangrijk detail is het trainingstoken. In captions staat bijvoorbeeld:
h3nkd3 vr135, The image is a close-up portrait of an elderly man's face. The man appears to be in his late 60s or early 70s, with gray hair that is slightly disheveled and falls over his shoulders. His eyes are closed, and his expression is peaceful and serene. He has a slight smile on his lips and his eyebrows are slightly furrowed. He is wearing a dark blue polo shirt with a collar. The background is white, making the man the focal point of the image.Zo’n token voorkomt dat het model bestaande associaties met gewone namen mengt met de persona. “Roos” kan bijvoorbeeld een naam zijn, maar ook een bloem. Een uniek token geeft de LoRA een duidelijker anker.
Het trainen zelf blijft een iteratief proces. Een LoRA kan ondertraind zijn, waardoor de persona niet genoeg lijkt, of overtraind, waardoor het model trainingsbeelden te letterlijk kopieert.
Kohya-SS kan trainingslogs naar TensorBoard schrijven:
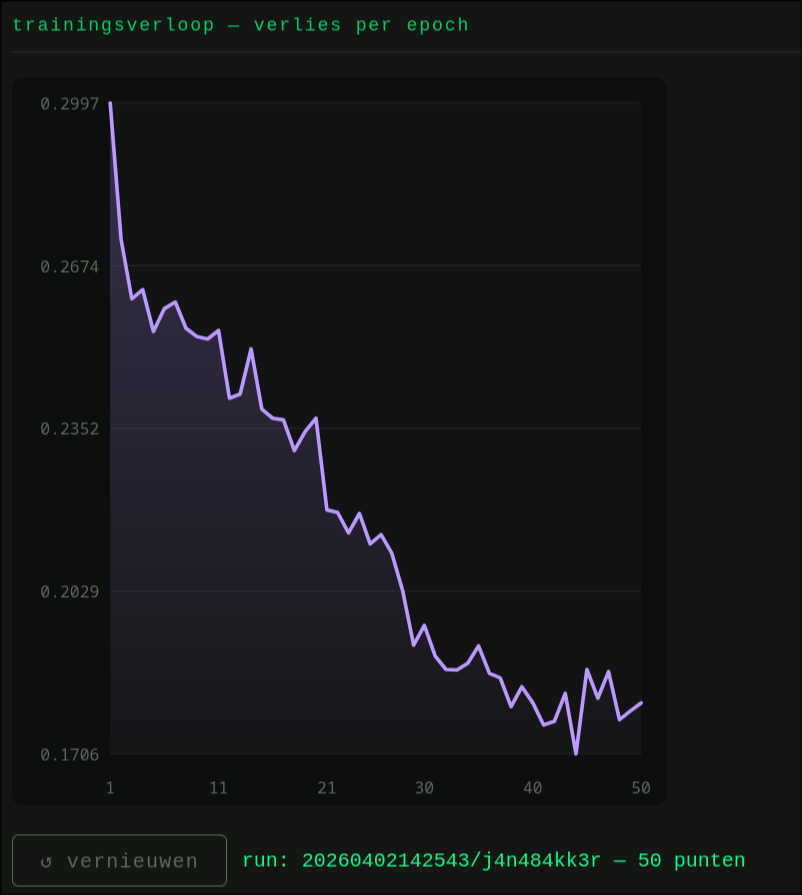
De loss-grafiek is een nuttige weergave van het LoRA-trainingstraject. Tijdens de training leert de LoRA om afbeeldingen uit de dataset te reconstrueren vanuit een afbeelding die alleen uit ruis bestaat (latent image).
De waarden op de Y-as zijn gebaseerd op het verschil tussen de door het model gegenereerde afbeelding en de oorspronkelijke afbeelding uit de dataset. Dit proces wordt herhaald voor alle afbeeldingen in de dataset gedurende meerdere trainingsstappen en epochs.
Dalen in de grafiek kunnen interessante checkpoints zijn om te testen omdat de loss daar relatief laag is, wat erop wijst dat het model de trainingsdata op dat moment goed heeft geleerd. Ze garanderen echter niet dat de output visueel de beste is. De uiteindelijke selectie vraagt daarom altijd om handmatige beoordeling.
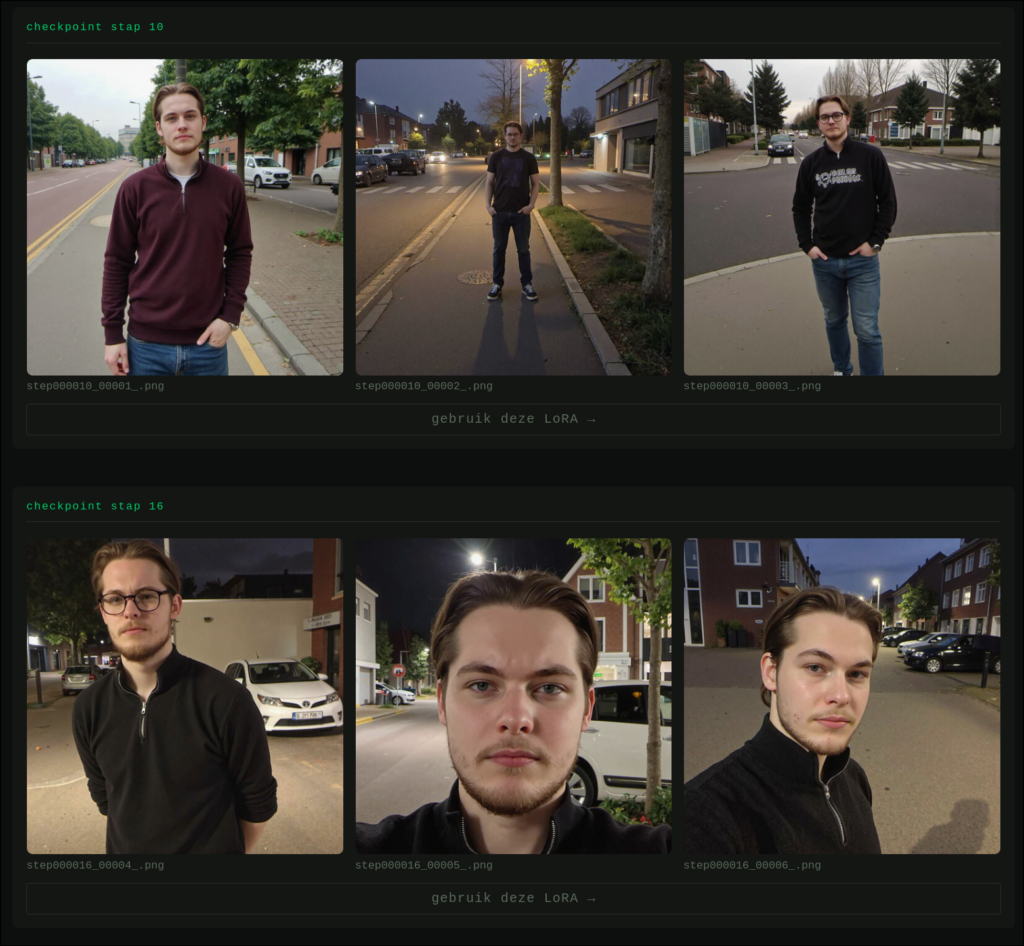
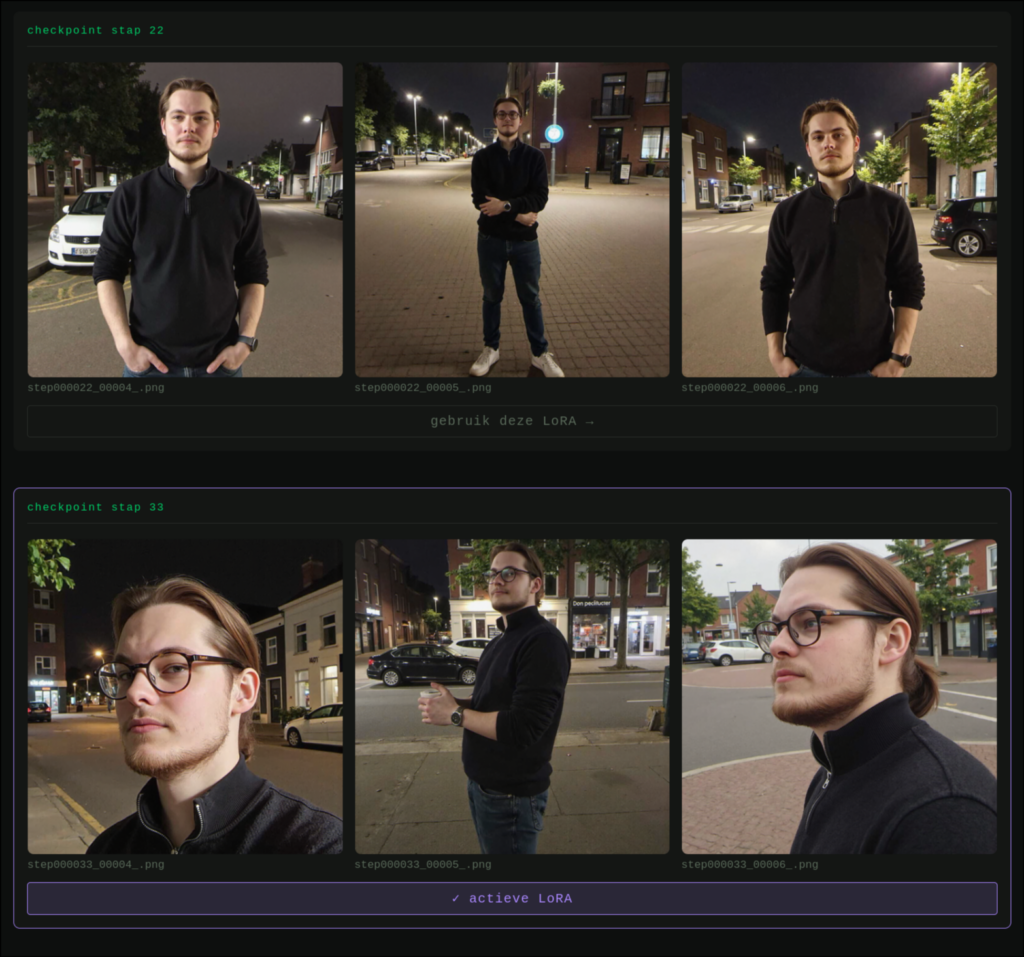
Latere checkpoints kunnen beter worden, maar niet altijd.
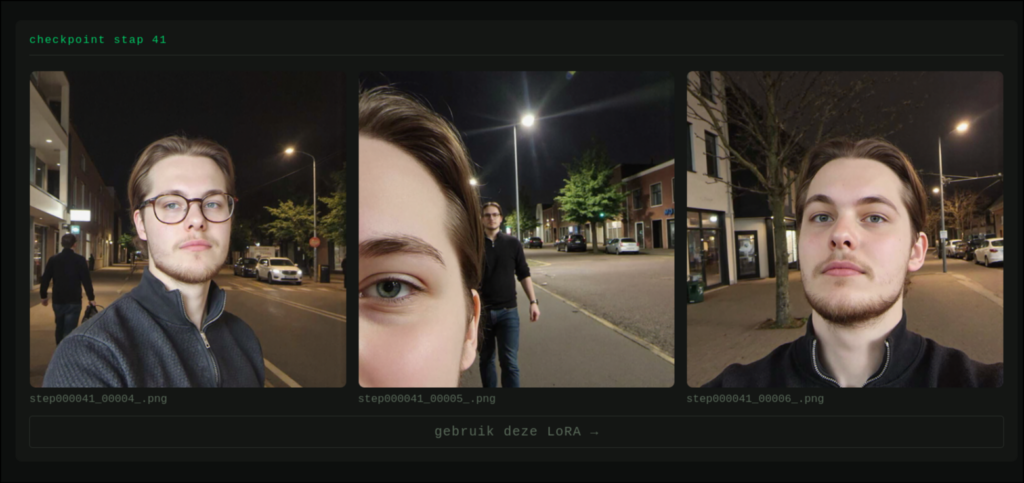
In dit voorbeeld ontstaat zelfs een dubbel personage. Daarom test je meerdere checkpoints en kies je de LoRA die in de praktijk het meest bruikbaar is.
Met een goede LoRA kun je dezelfde persoon in meerdere contexten laten terugkomen.

prompt: d1g1cam, wel-lit, Low-resolution photo, shot on a mobile phone, daytime, cafeteria. Solo foto of c0l1n5m17 wearing a formal attire, relaxed look, closed mouth.

prompt: d1g1cam, wel-lit, Low-resolution photo, shot on a mobile phone, daytime, in a park. Solo foto of c0l1n5m17 sitting with his dog, wearing a casual green hoodie, relaxed look, closed mouth.
Voor social-engineeringtests is dit vooral nuttig wanneer een pretext meerdere contactmomenten heeft. De persona moet dan niet alleen inhoudelijk kloppen, maar ook visueel herkenbaar blijven.
Wat organisaties hiervan kunnen leren
AI-beeldgeneratie maakt social engineering niet automatisch succesvol, maar het verlaagt wel de moeite die nodig is om een verhaal geloofwaardig te ondersteunen. De verdedigende les is daarom niet: “leer elk AI-beeld herkennen.” De les is: bouw processen die niet afhankelijk zijn van beeldvertrouwen alleen.
Een paar praktische maatregelen:
- Controleer externe monteurs, leveranciers en bezoekers via bekende interne kanalen.
- Behandel foto’s, screenshots en meldingen als context, niet als bewijs.
- Maak duidelijk wie uitzonderingen mag goedkeuren en hoe spoedverzoeken worden gecontroleerd.
- Neem AI-gegenereerde beelden mee in awareness-trainingen en tabletop-oefeningen.
- Rapporteer verdachte situaties laagdrempelig, ook als iemand overtuigend beeldmateriaal laat zien.
Vooruitkijken
Self-hosted diffusion-modellen worden snel beter. ComfyUI maakt het relatief eenvoudig om workflows van anderen te testen, aan te passen en te integreren in een eigen tool. Dat is technisch leuk, maar voor security vooral relevant omdat aanvallers dezelfde ontwikkeling kunnen benutten.
Voor verdedigers ligt de kans in gecontroleerd oefenen. Door AI-ondersteunde scenario’s binnen een veilige opdracht te testen, ontdek je waar medewerkers, procedures en aannames nog te veel vertrouwen op wat er visueel overtuigend uitziet. Hoe realistischer de beelden worden, hoe belangrijker het wordt dat verificatieprocessen sterker zijn dan de pixels.
Dit onderzoek is uitgevoerd & geschreven door Collin Smit:

Collin Smit
Stagiair Platform Engineering